Publications
2024
- EMNLP
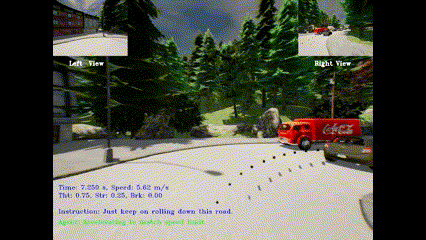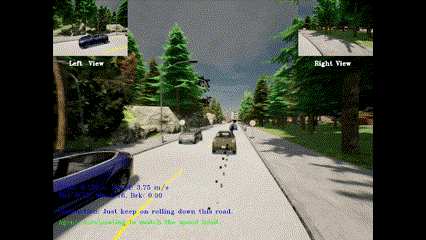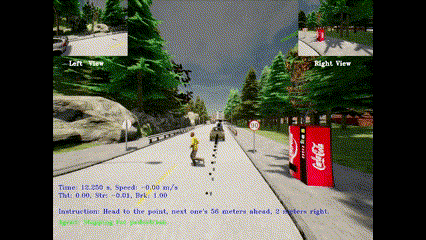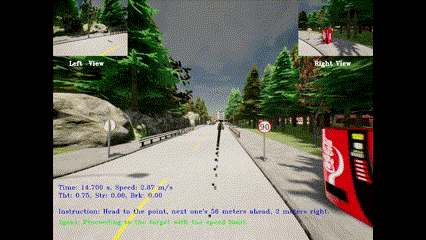 Learning Autonomous Driving Tasks via Human Feedbacks with Large Language ModelsIn Findings of the Association for Computational Linguistics: EMNLP, 2024
Learning Autonomous Driving Tasks via Human Feedbacks with Large Language ModelsIn Findings of the Association for Computational Linguistics: EMNLP, 2024 - CVPR
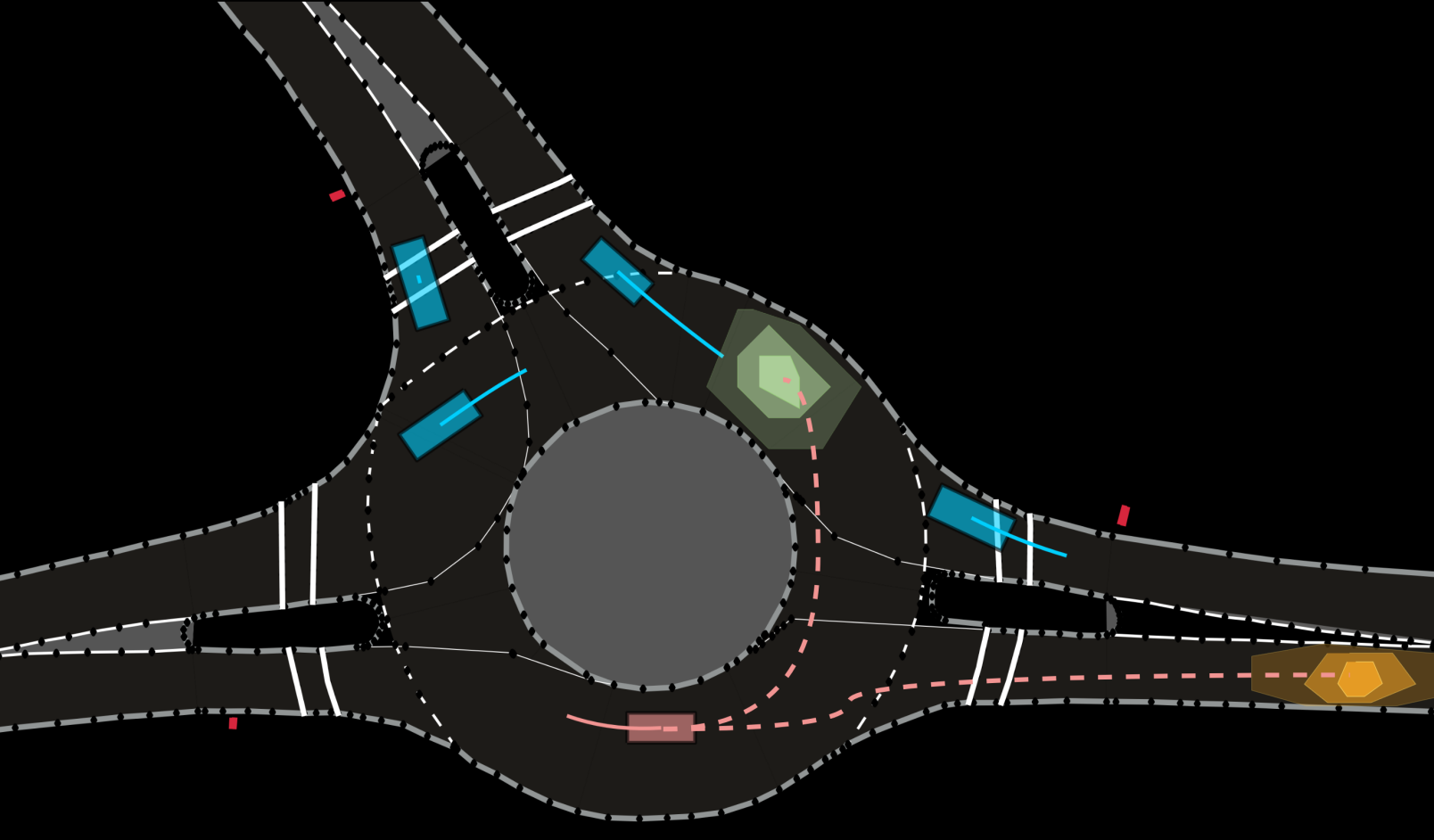 Quantifying Uncertainty in Motion Prediction with Variational Bayesian MixtureIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
Quantifying Uncertainty in Motion Prediction with Variational Bayesian MixtureIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024 - ITSM
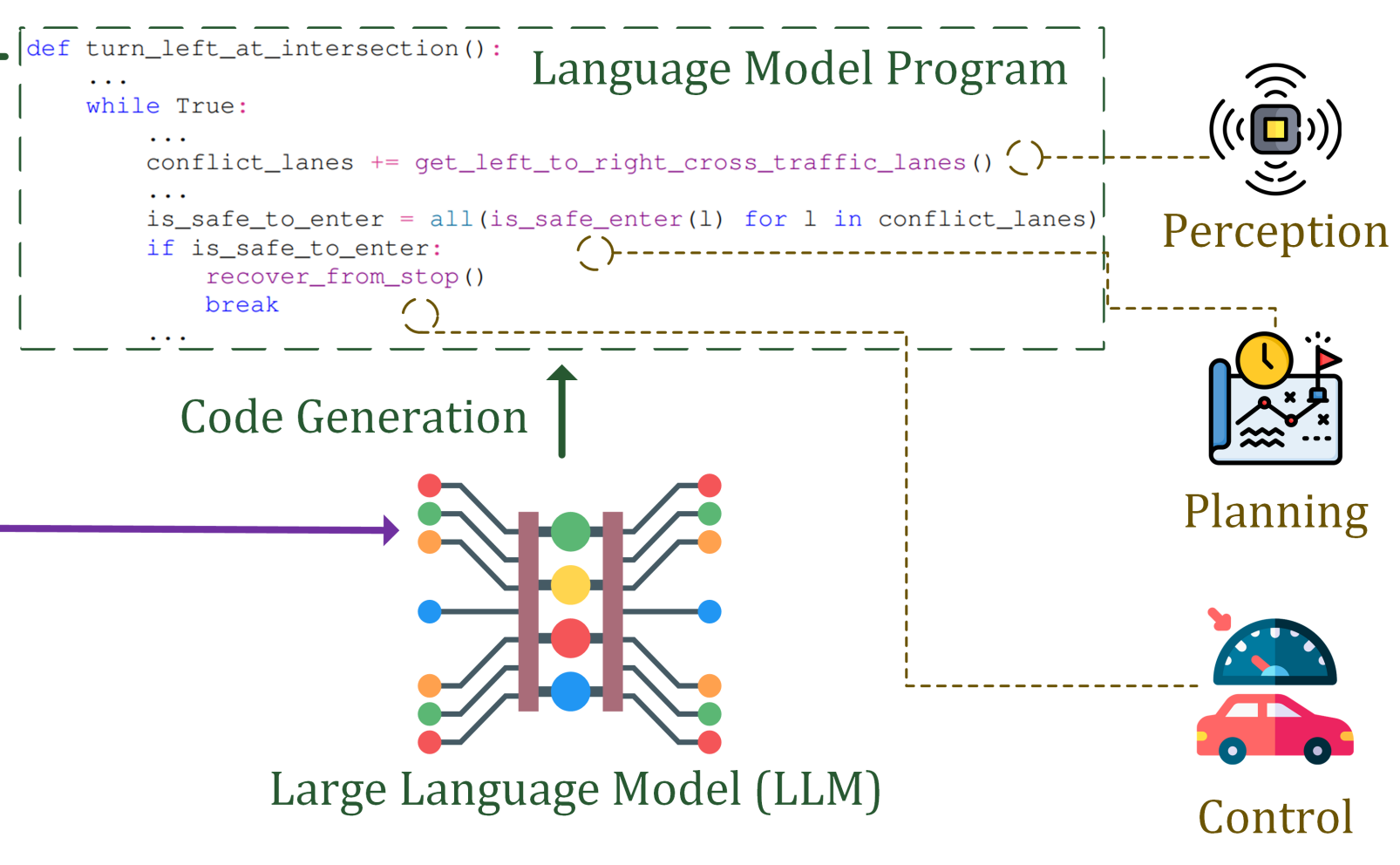
 Receive, Reason, and React: Drive as You Say, With Large Language Models in Autonomous VehiclesIEEE Intelligent Transportation Systems Magazine, 2024
Receive, Reason, and React: Drive as You Say, With Large Language Models in Autonomous VehiclesIEEE Intelligent Transportation Systems Magazine, 2024 - T-IV
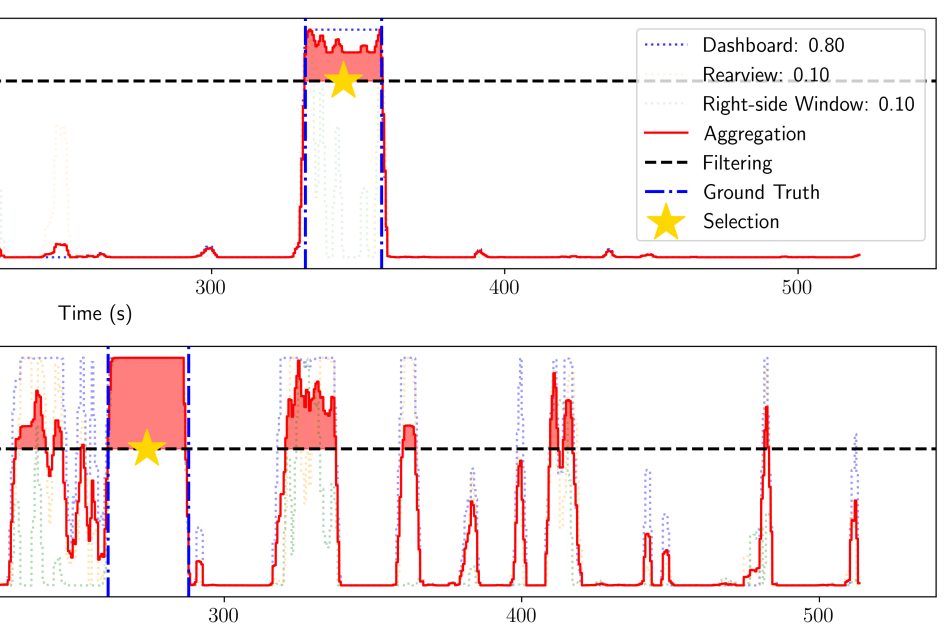
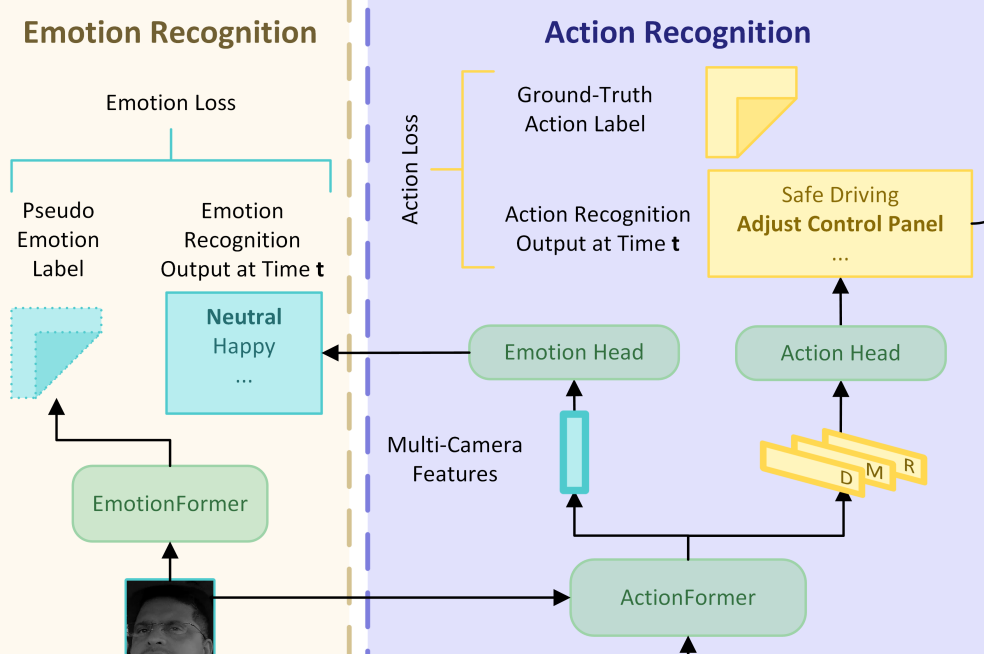 Driver Digital Twin for Online Recognition of Distracted Driving BehaviorsIEEE Transactions on Intelligent Vehicles, 2024
Driver Digital Twin for Online Recognition of Distracted Driving BehaviorsIEEE Transactions on Intelligent Vehicles, 2024


2023
- T-IV
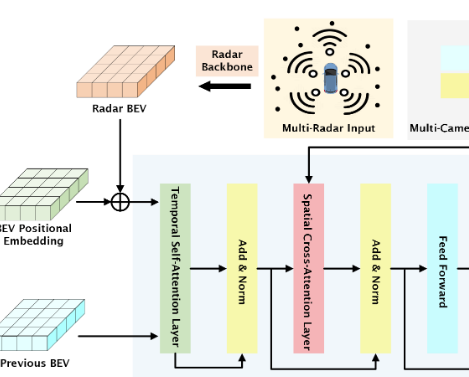 REDFormer: Radar Enlightens the Darkness of Camera Perception With TransformersIEEE Transactions on Intelligent Vehicles, 2023
REDFormer: Radar Enlightens the Darkness of Camera Perception With TransformersIEEE Transactions on Intelligent Vehicles, 2023 - UAI
 Mitigating Transformer Overconfidence via Lipschitz RegularizationIn Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, 2023
Mitigating Transformer Overconfidence via Lipschitz RegularizationIn Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, 2023 - ITSC
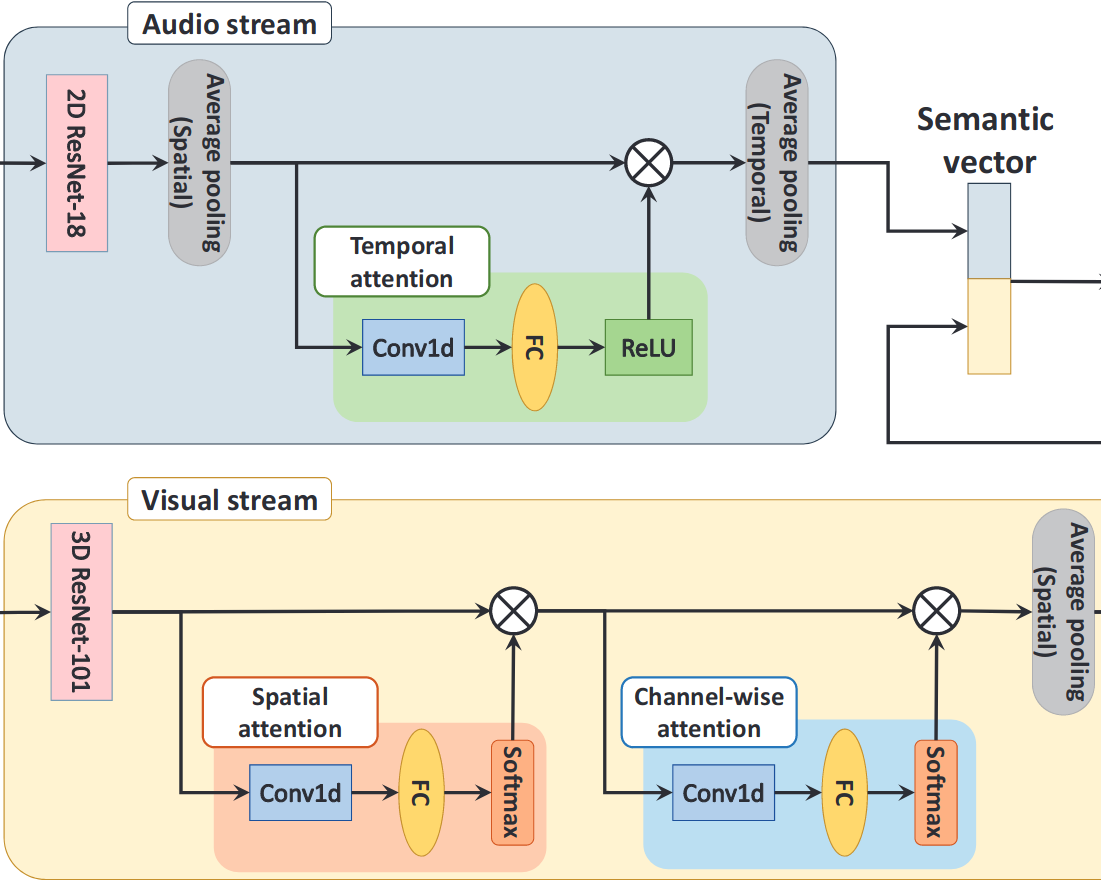
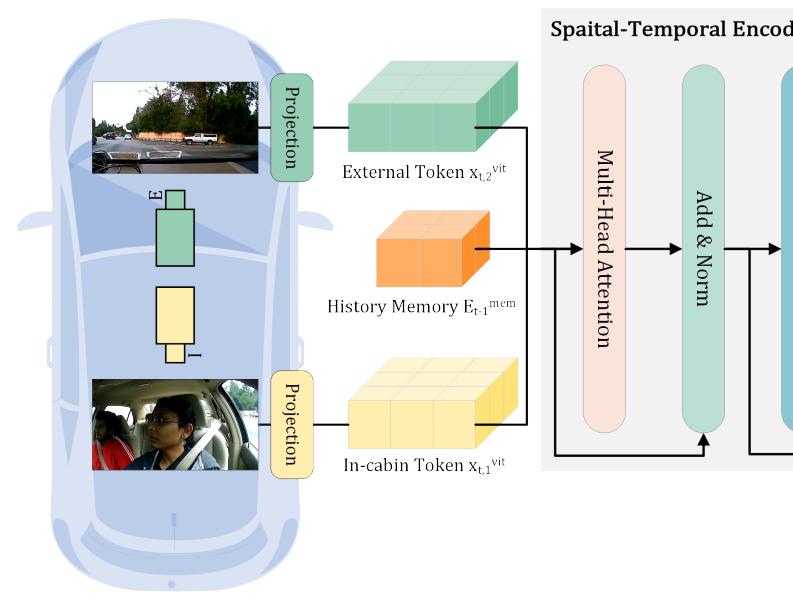 CEMFormer: Learning to Predict Driver Intentions from In-Cabin and External Cameras via Spatial-Temporal TransformersIn IEEE International Conference on Intelligent Transportation Systems, 2023
CEMFormer: Learning to Predict Driver Intentions from In-Cabin and External Cameras via Spatial-Temporal TransformersIn IEEE International Conference on Intelligent Transportation Systems, 2023 - CVPRW
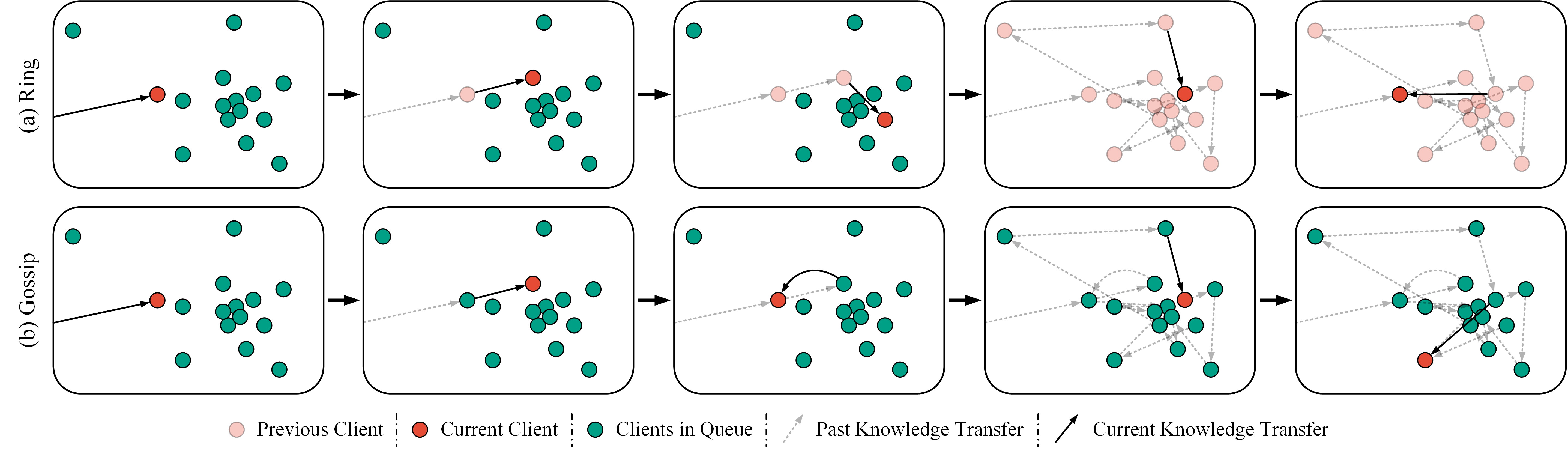 Peer-to-Peer Federated Continual Learning for Naturalistic Driving Action RecognitionIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2023
Peer-to-Peer Federated Continual Learning for Naturalistic Driving Action RecognitionIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2023